![]()

Kihwan Kim (김기환)
VP at Samsung Electronics
Head of XR and Immsersive SW
Ph.D. in Computer Science
Georgia Institute of Technology
Contact :
email) kihwan23 dot kim at gmail

|
|
||
|
|
Kihwan Kim (김기환) VP at Samsung Electronics
Head of XR and Immsersive SW Georgia Institute of Technology Contact : email) kihwan23 dot kim at gmail |
|
|
I am currently a corporate vice president in Mobile communications division (MX/무선사업부) in Samsung Electronics. I have led several teams in computer vision, deep learning (on-device inference),
camera pipeline, XR (AR/VR) and Avatar for Samsung's flagship Galaxy phones and various form factors. |
|
|
News, recently released code, talks and dataset |
|
|
2020 to 2022 (at Samsung)
: Links for flagship models and other commercialization topics and projects were added
|
|
|
Main projects |
|
|
[SDC 2022]
|
Samsung Galaxy Avatar: new SDK announcements |
|
AR Emoji: Your avatar, your experience
|
|
[NeurIPS20]

|
Reconstructing a temporally consistent non-rigid object instances |
|
Online Adaptation for Consistent Mesh Reconstruction in the Wild
|
|
[ECCV2020]
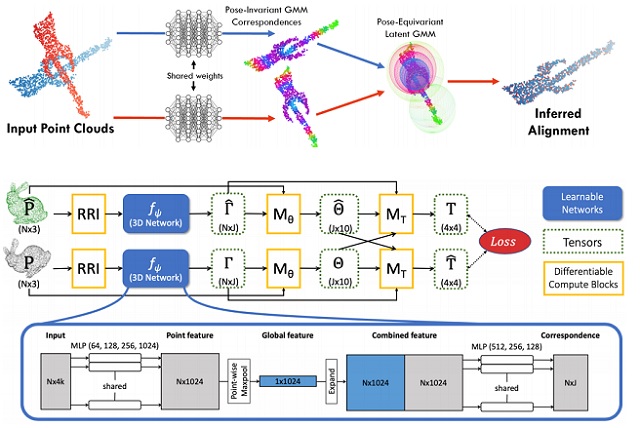
|
Learning Latent GMM for 3D Registration |
|
DeepGMR: Learning Latent Gaussian Mixture Models for Registration
|
|
[ECCV2020]

|
Single view 3D reconstruction with semantic consistency |
|
Self-supervised Single-view 3D Reconstruction via Semantic Consistency
|
|
[CVPR2020]
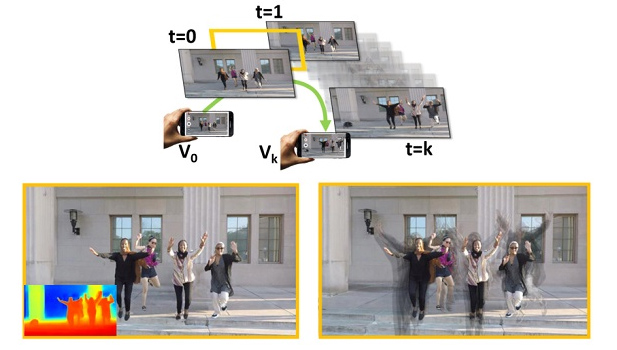
|
Novel View Synthesis for Dynamic Scenes |
|
View Synthesis of Dynamic Scenes with Globally Coherent Depths
|
|
[CVPR2020]

|
Two-shot SVBRDF Estimation |
|
Two-shot Spatially-varying BRDF and Shape Estimation
|
|
[CVPR2020]

|
Stereo Depth with binary classifications |
|
Bi3D: Stereo Depth Estimation via Binary Classifications
|
|
[WACV2020]

|
Non-rigid Multiview Stereo |
|
NRMVS: Non-Rigid Multi-view Stereo
|
|
[ICCV19]

|
Inverse Rendering of an Indoor Scene |
|
Neural Inverse Rendering of an Indoor Scene from a Single Image
|
|
[CVPR19]
Oral

|
Plane detection, segmentation and 3D reconstruction |
|
PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
|
|
[CVPR19]
Oral *Best paper finalist.
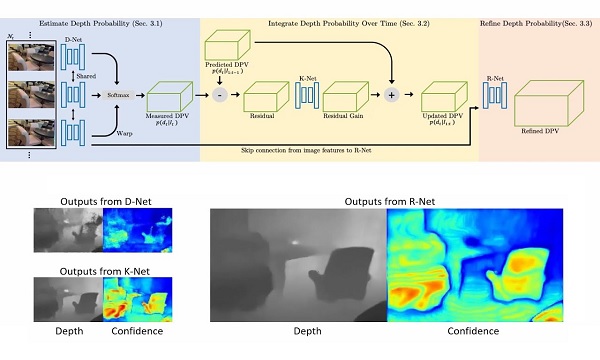
|
Neural RGB-D Sensing: Depth estimation from a video |
|
Neural RGB-D Sensing: Depth estimation from a video
|
|
[CVPR19]
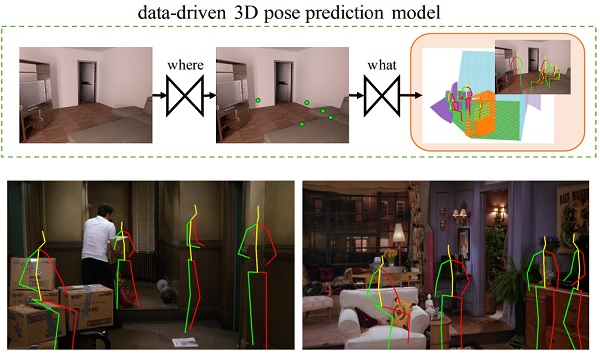
|
Putting Human in a Scene: 3D Human Affordance |
|
Putting Humans in a Scene: Learning Affordance in 3D Indoor Environments
|
|
[CVPR19]

|
Unsupervised Joint Learning of Depth, Pose, Flow and Motion |
|
Competitive Collaboration: Joint Unsupervised Learning of Depth, CameraMotion, Optical Flow and Motion Segmentation
|
|
[ECCV18]

|
Learning Rigidity for 3D Scene Flow Estimation |
|
Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation
|
|
[ECCV18]
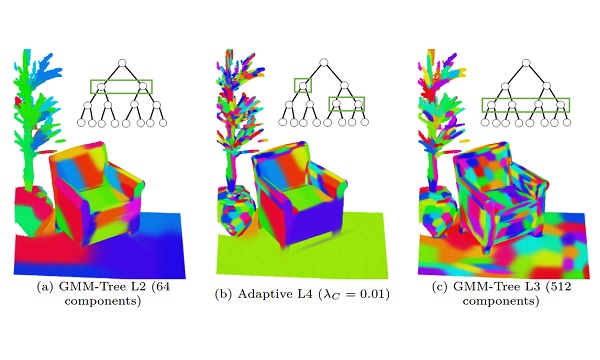
|
Hierarchical GMM for 3D Point Cloud Registration |
|
HGMR: Hierarchical Gaussian Mixtures for Adaptive 3D Registration
|
|
[CVPR18]
Spotlight Oral
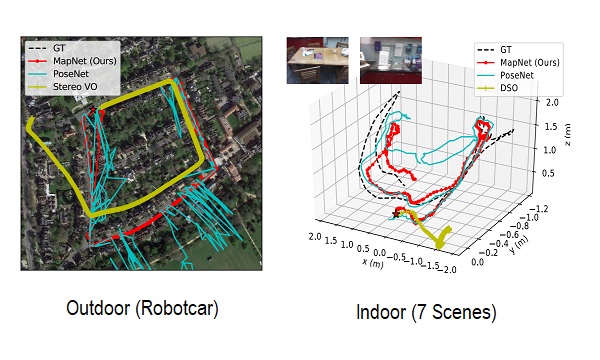
|
Learning-based Camera Localization (MapNet) |
|
Geometry-Aware Learning of Maps for Camera Localization (MapNet)
|
|
[ICCV17]
Oral
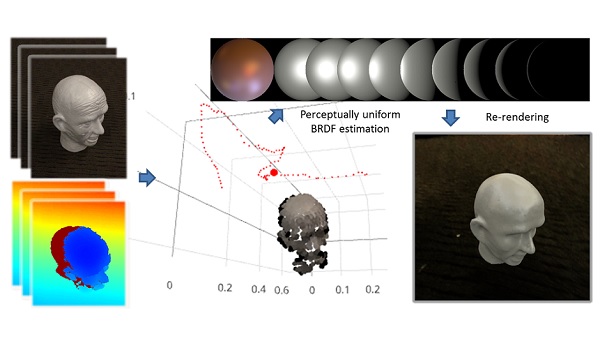
|
Deep Learning-based Reflectance Estimation On-the-fly |
|
A Lightweight Approach for On-the-Fly Reflectance Estimation
|
|
[ICCV17]
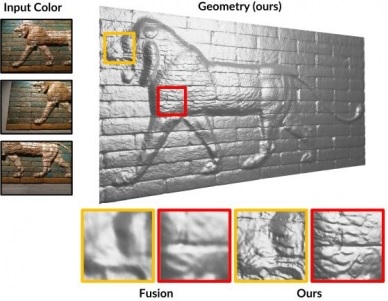
|
Joint Optimization of Geometry, Color and Lighting for 3D Reconstruction |
|
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
|
|
[3DV17]
Oral

|
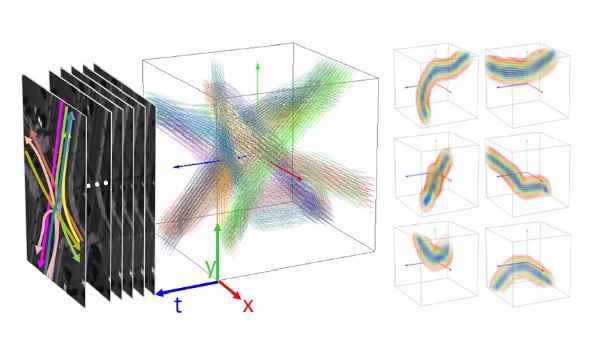
Multi-frame 3D Scene Flow Estimation |
|
Multiframe Scene Flow with Piecewise Rigid Motion
|
|
[CVPR16]
Oral

|
Accelerated Generative model (GMM) for 3D Vision |
|
Accelerated Generative Models for 3D Point Cloud Data
|
|
[CVPR16]

|
Online classification of Dynamic Hand Gestures with R3DCNN |
|
Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks
|
|
[DARPA]
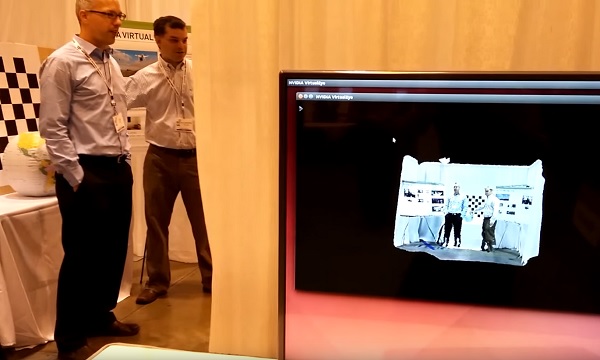
|
VirtualEye: Real-time 3D Reconstruction for Fast Free View Video |
|
NVIDIA VirtualEye: Real-time Fast Free View Video
|
|
[3DV15]
Oral
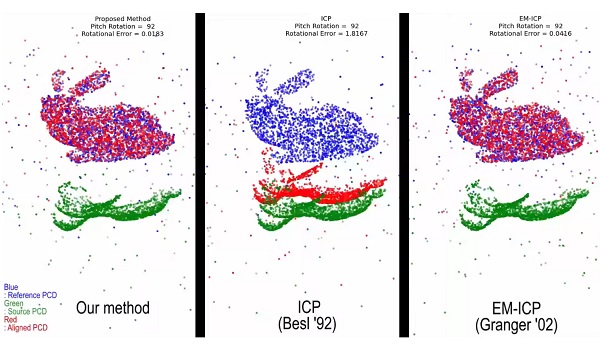
|
Fast and accurate PCD registration with GMM |
|
MLMD: Maximum Likelihood Mixture Decoupling for Fast and Accurate Point Cloud Registration
|
|
[EGSR15]
Oral

|
Physically-based Rendering for Mixed and Augmented Reality |
|
Filtering Environment Illumination for Interactive Physically-Based Rendering in Mixed Reality
|
|
[CVPRW15]
Oral
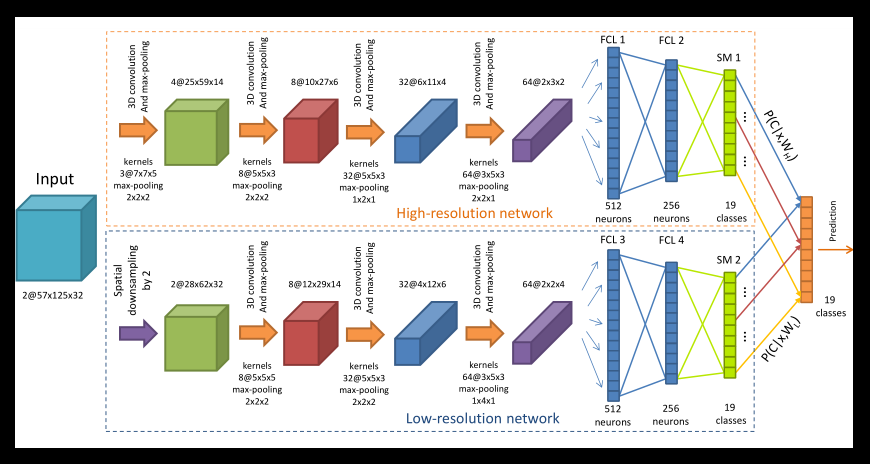
|
3D CNN for Dynamic Hand Gesture Recognition |
|
Hand Gesture Recognition with 3D Convolutional Neural Networks
|
|
[FG15] [RIDARCon15]
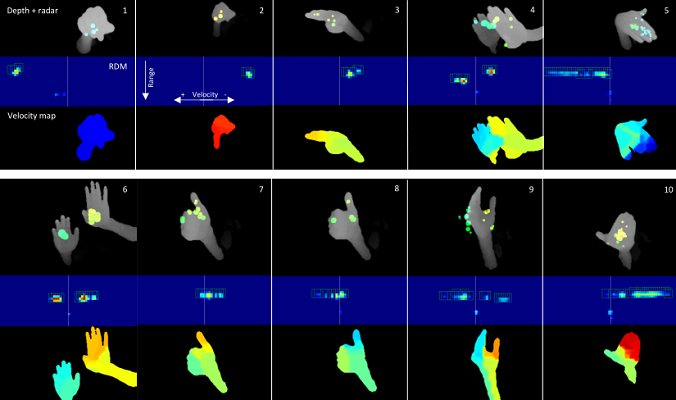
|
Multi-sensor Deep Learning architecture for Gesture recognition |
|
Multi-sensor System for Driver's Hand-Gesture Recognition
|
|
[3DV14]
Oral

|
DT-SLAM: Robest SLAM with Adaptive Triangulation for Rotation |
|
DT-SLAM: Deferred Triangulation for Robust SLAM
|
|
[TOG/SIGGRAPHA13]

|
WYSIWYG Viewfinder: Real-time Segmentation and Editing |
|
WYSIWYG Computational Photography via Viewfinder Editing
|
|
[CVPR12]
|
Prediction of Camera Motions with Gaussian Process Regression |
|
Detecting Regions of Interest in Dynamic Scenes with Camera Motions
|
|
[ICCV11]
|
Gaussian Process Regression Flow (GPRF) |
|
Gaussian Process Regression Flow for Analysis of Motion Trajectories
|
|
[CVPR10]
|
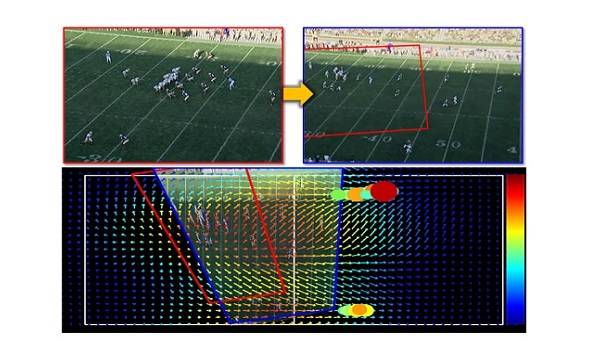
Global Motion Prediction for Automated Broadcasting System |
|
Motion Fields to Predict Play Evolution in Dynamic Sports Scenes
|
|
[CVPR10]
|
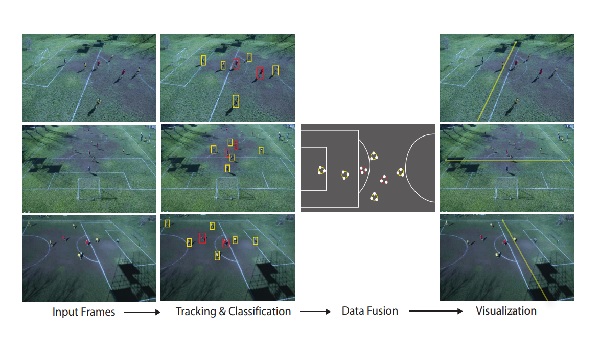
Player Tracking and Localization with Multiple Cameras |
|
Player Localization using Multple Static Cameras for Sports
|
|
[ISMAR09]
Oral

|
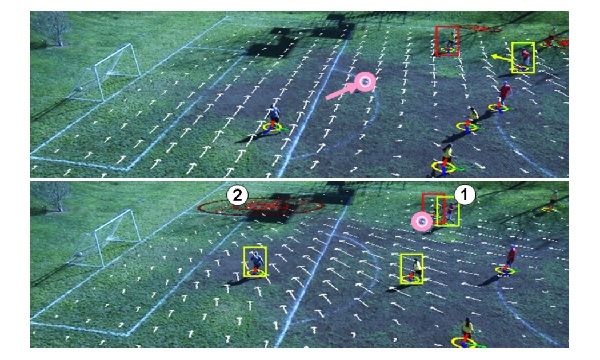
Augmenting Earth-Maps with Dynamic Information |
|
Augmenting Aerial Earth Maps with Dynamic Information
|
|
[JGT]
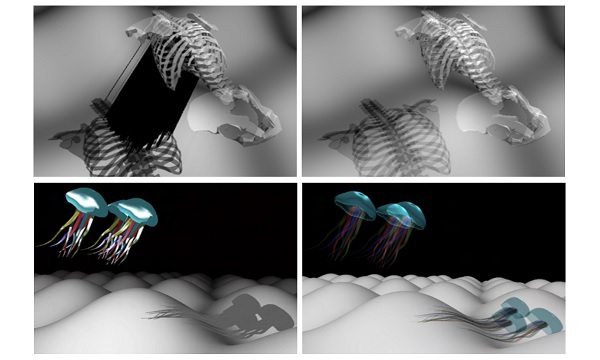
|
Real-time Transparent-Colored Shadow Volume |
|
A Shadow Volume Algorithm for Opaque and Transparent Non-Manifold Casters
|
|
[ISWC08]
Oral
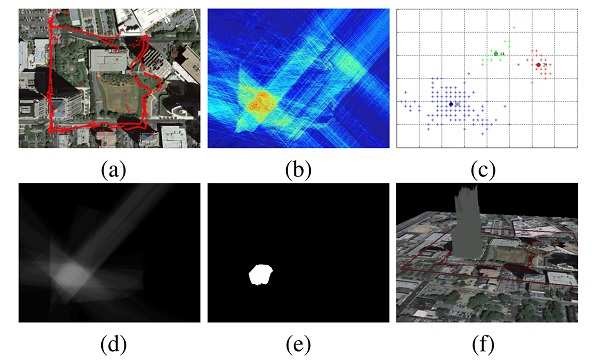
|
GPSRay: 3D Reconstruction of Urban Scenes using GPS |
|
Localization and 3D Reconstruction of Urban Scenes Using GPS
|
|
[STAR/SAIT 08]

|
Video based Non-Photorealistic Rendering |
|
Video based Non-Photorealistic Rendering
|
|
[ACMMM 06]

|
Video based Non-Photorealistic Rendering |
|
Interactive Mosaic Generation for Video Navigation
|
|
[Tech06]

|
Face Recognition using Generalized SVD |
|
Face Recognition using Generalized Singular Value Decomposition
|
|
[Tech05]

|
Real-time Face Detection |
|
Face Detection with Adaboost and Morphology Operators
|
|
|
Research and Development at Samsung SDS IT R&D Center |
|
|
|
|
[Samsung01]
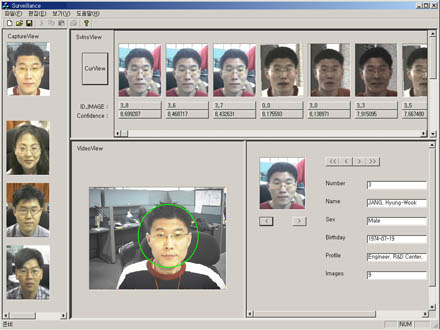
|
ViaFace: Face Identification System |
|
Face Detection with Adaboost and Morphology Operators
|
|
[Samsung02]
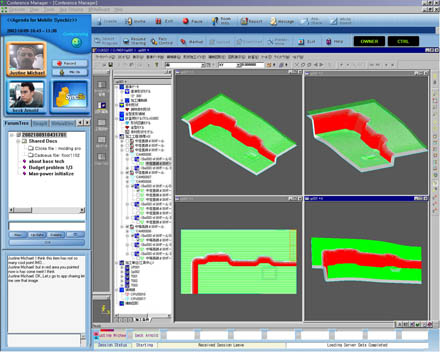
|
Syncbiz: Real-time Collaboration System |
|
Samsung Real-time Collaboration System
|
|
[Samsung04]

|
IP-STB Framework : LivingWise CS (LWCS) |
|
LivingWiseCS (LWCS) Samsung's Smart City STB Framework
|
|
![[SNU]](https://gsds.snu.ac.kr/wp-content/uploads/editor/50/EDITOR_20210526145124_oCePpSJs5N.jpg){kind=link}